AIってなに?
メニューに戻る
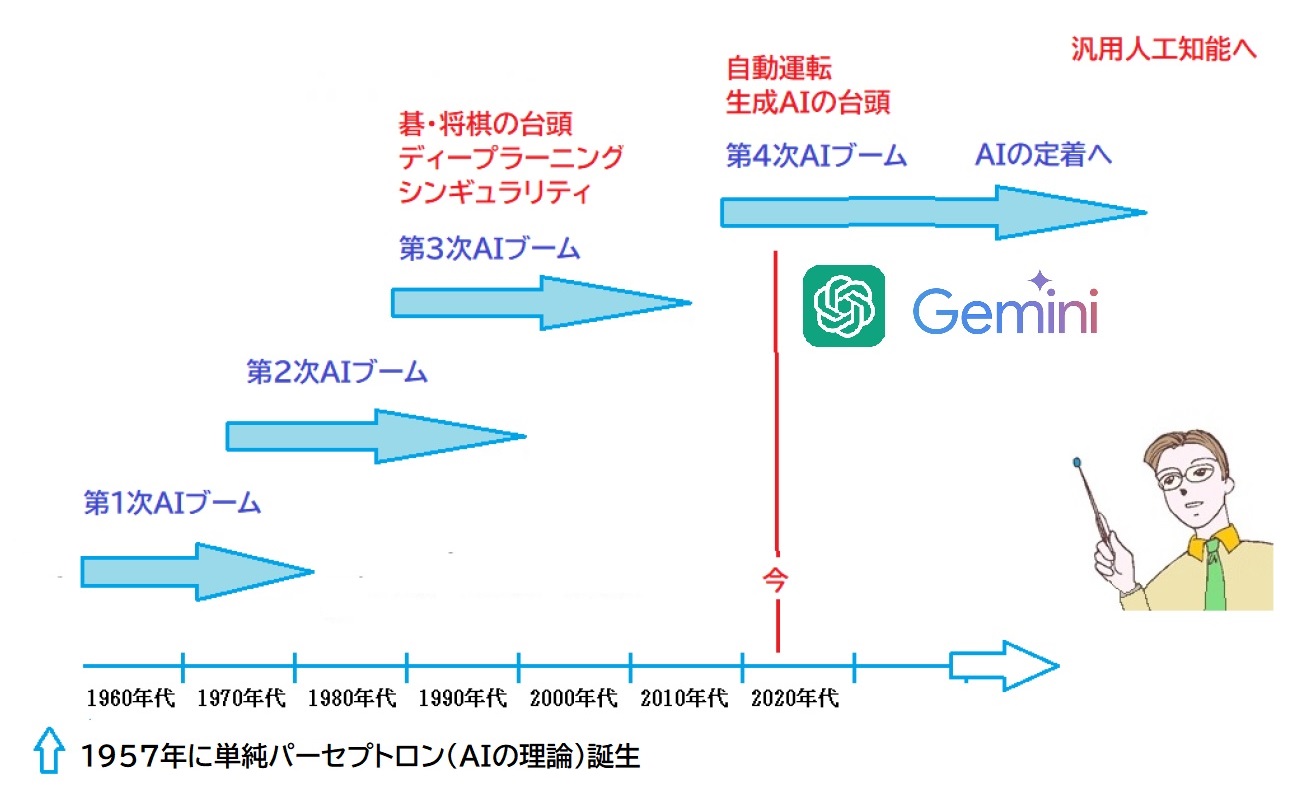
AIの歴史
AIは1957年には生まれていた➡単純パーセプトロンという理論!
▼
何度かAIブームが起き、強い将棋などができたが一般人の対象ではなかった!
▼
2022年11月に生成AIのChatGPTが発表され、進撃の巨人化し、一気に社会に広まった!
▼
多くの職業を奪うと同時に、新しいビジネス領域もでき、AIを使わない社会はありえなくなった!
進撃の巨人
2022年にChatGPTが発表され、CEOのアルトマン氏が翌年、岸田首相(当時)に面会し、生成AIの普及を促進させました。いち早く日本に来たのは、日本が応用が上手な国民であり、ChatGPTの活用に日本を選んだ経緯があります。その予想通り、GoogleのGemini、MicrosoftのCoPilotなど、他社の生成AIも登場し、その利用は一気に広まって行きました。
なにしろプロンプトという質問や指示をするテキストを描くだけで、目的の事をしてくれるので、事務や論文や小説の執筆だけでなく、絵や写真の生成、果ては「ジブリ風にして・・・」というだけで、入力した写真をジブリ風の絵にしてしまいます。ちょっとしたコンサルティング業やカウンセリングだけでなく、本格的な論文やイラストやプログラミングまで作成してしまうので、ちょっとした事務員やデザイナーやプログラマーの仕事は奪われます。
ただ逆もまたありで、単純作業はAIに任せ、より人間として高度な部分に時間を割くことができます。新しいビジネスチャンスでもあるわけです。コールセンターもAIに任せれば、クレーム対応でストレスを感じることはありません。絵を描くことは楽しいのですが、もしコマ割り漫画を修正するとなると大変な作業です。そういったものはAIに任せ寝ている間に修正してもらいます。人間は良し悪しの判断や、文化的なAIができない作業を行います。進撃の巨人でしたが、巨大なAIビジネスの幕開けでもあります。

生成AI ChatGPT
ChatGPTやGeminiやCopilotなどの生成AIに、事務処理、論文や小説の執筆、イラストの作成など多くの仕事をさせることができます。これはプロンプトというAIに指示をするテキストを与えることでできるので、誰でもが簡単に前述のものを作成できます。東大の入試問題を解いてもらったというのもあります。基本的に文章の理解と解読が得意です。音声をテキストに変換したり翻訳も得意なので、それで用意したテキストを、目的に応じたプロンプトで校正すれば、目的の文章が出来上がります。この例は元原稿のテキストのストーリーを漫画にしたいので、コマ割りにしてくれるようにプロンプトで指示したものです。

AIが描く絵
絵はプロンプトで指示をして書いてもらいますが、同じ絵を2度と描けません。記憶できないからです。写真や写真に近い実写型の絵は上手く書けますが、二次元漫画でディフォルメが大きいものは苦手です。これは写真などはデータセットが多くあるので、AIは学習しているのですが、二次元漫画は実写ではないので、漫画それぞれが(作者によって)あまりにも違うので、一つを覚えても、次の漫画には応用が利かないということになります。
また実写型でないものは経験不足から文化的見地に劣り、人間の感性から離れたものが出来上がってきます。野菜の惑星の「トマトのような女の子と、地球人に変身した時を描いて」と指示したものがこれです。右側は人間のアニメ学校の生徒によるものです。AIに文化的感性を求めるには、まだ無理があるかもしれません。

連載まんがを描く
このことから絵に関してはプロンプトで指示した1枚の絵を描くことはできますが、絵を記憶させて同じ絵を描くことは(著作権が絡むせいか)できません。従って主人公や登場人物が同じ連載漫画を描くときは、「①生成AIでストーリーを書く」➡「②主人公や登場人物のキャラクターを描く」➡「③キャラクターを記憶する」➡「④別のツールで変え編集する」という順になります。ここでいう別のツール「AIトレーナー玲子」の「まんがグラフィックエディター」を用意しました。
まんがグラフィックエディター
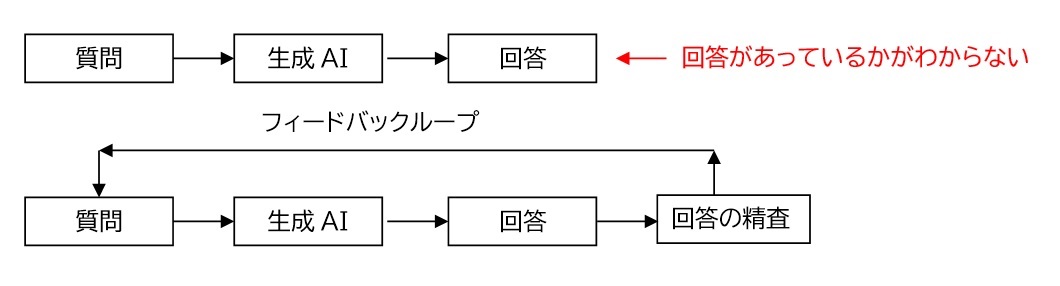
AIトレーナー玲子のメニューを変えたものです。前のものもあります。ここではデータが一方通行ではなく、ヒストリーデータと共に連続して流れている様子が描かれたいます。人間の脳の中ではデータが、縦横無尽に行きかっています。それで何とか答えを出しますが、それでも間違うことがあります。脳とはそういうものです。そこでこのような一方通行ではない、脳内のデータが必要になります。
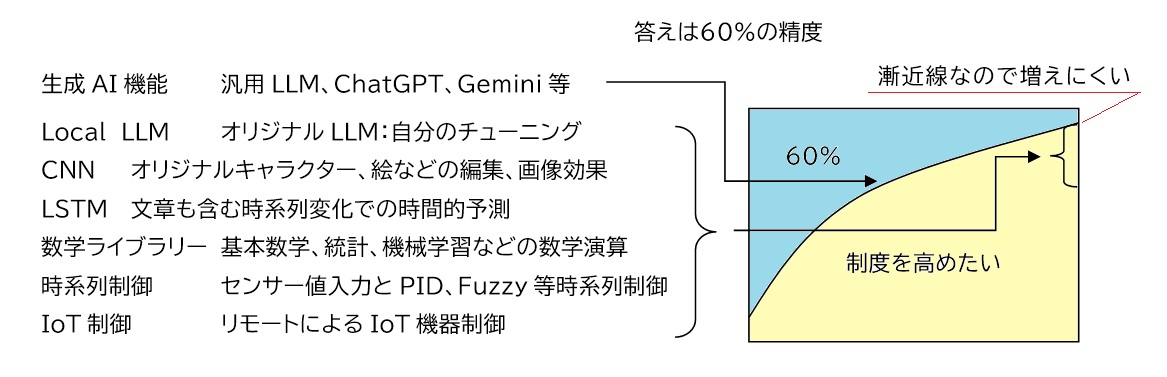
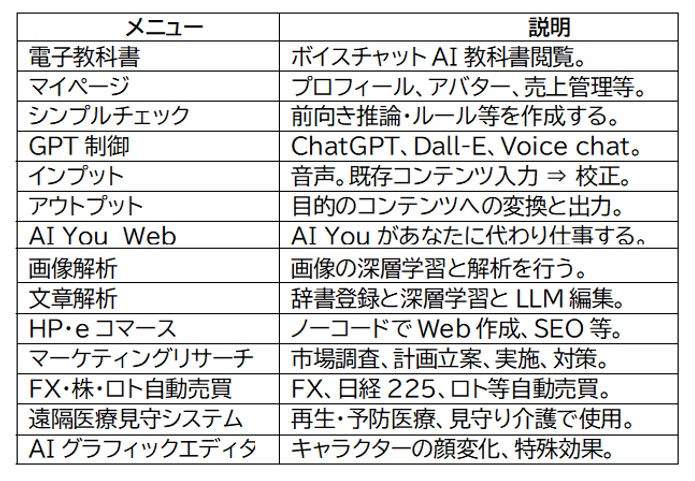
AIトレーナー玲子
特徴
1. 事務処理の効率化:書類や企画書などは、AIが自動作成し、人件費が低減できる。
2. 外注費低減:広告用コンテンツをAIが自動作成、市場調査して効率よく販売する。
3. 新規産業:自社の専門データを登録し、イノベーションビジネスを開始する。
目的
1,事務管理ソフトではなく、売上を生むソフトです。同時に安価なPCを何台も使って生産性を上げます。
2,コンテンツの制作や事務用書類の作成など、専用化された操作を効率的に行い人件費を抑制します。
3,WebアプリでAIアバターを作り、これが貴方のAI分身となり、AIにより仕事をし、対価を得ます。
4,LLMを内製化し自社の専門オリジナル生成AIを構築できるので、他社に対して差別化できます。
5,このPC1台で10人の人間と同じような働きをします。リース代5万円なら、5千円が給与です。
AI Webアプリ なっちゃん
松崎由美子ビジネスモデル:食養生の薦め
気虚とはなどのなどの漢方の説明だけでは他の説明書と同じである。ユーザーの日々の状況をLLMでフィードバックし、他では得られない情報を得られるようにする。
大川芳子ビジネスモデル:クッキングソムリエ
料理の写真からカロリー、栄養素(ビタミン、ミネラル)を計算するが、普段食べている料理の栄養素を積算しておいて、足りない栄養素を指示し、レシピ等にする。LLMではよいレシピ情報をチューニングする。
柳田国男ビジネスモデル:芥川賞を取ろう!
日本語専用のLLMでない限り、汎用LLMは英語に強い。日本語の方言や、独特な言い回しなどの文章表現などをチューニングするが、大学の日本語学部などと連携する。彼らはLLMは興味があると思う。

マルチAIサーバー真一郎
大岩伸之ビジネスモデル:コンテンツ制作
オリジナルLLMでは深層学習で画像を変換するための画像エフェクターのアルゴリズムを想定させるようなファインチューニングを行う。
・LLMサーバー仕様 ⇒ OSはUbuntuで、Windowsではありません。
・価格 ⇒ GPUによるがデスクトップで50万円からと考えています。
・性能 ⇒ ユーザーの同時アクセス数ですが数ユーザーです。
・速度 ⇒ GPUの性能に寄りますが、数秒以上かかると考えられます。
・使用方法 ⇒ Webサーバーと連携してユーザーのプロンプトに返答する。
・データチューニング ⇒ かなりの時間がかかるので、協力できる機関や人と連携して入力を行う。
・チューニングサンプル ⇒ 上記の使用例を載せておきますが、とにかく時間のかかる作業です。
以下はスペックです。WindowsかLinuxで提供します。

Copyright(C) Nobuyuki Oiwa Feptmber 2025